+91 9903662244
hello@dexlabanalytics.com
MENU
Home
Who We Are
Our Story
Trainer’s Profile
Our Courses
Advanced Certificate in Credit Risk Modeling with Machine Learning
Advanced Certificate in IFRS 9 Modeling
Advanced Certificate in Credit Scorecard Modeling
Market Risk Analytics and Modelling
Customer and Marketing Analytics & Modelling
Data Science and Machine Learning with AI Certification
Python Programming Certification
R Programming Certification
Business Analytics and Data Visualization Certification
MS Excel VBA Certification
Tableau BI & Visualization Certification
Alteryx Certification
SQL Certification
Corporate Trainings
Placements
Job Updates
Blog
Contact Us
Tag Archive: Big data training in Gurgaon
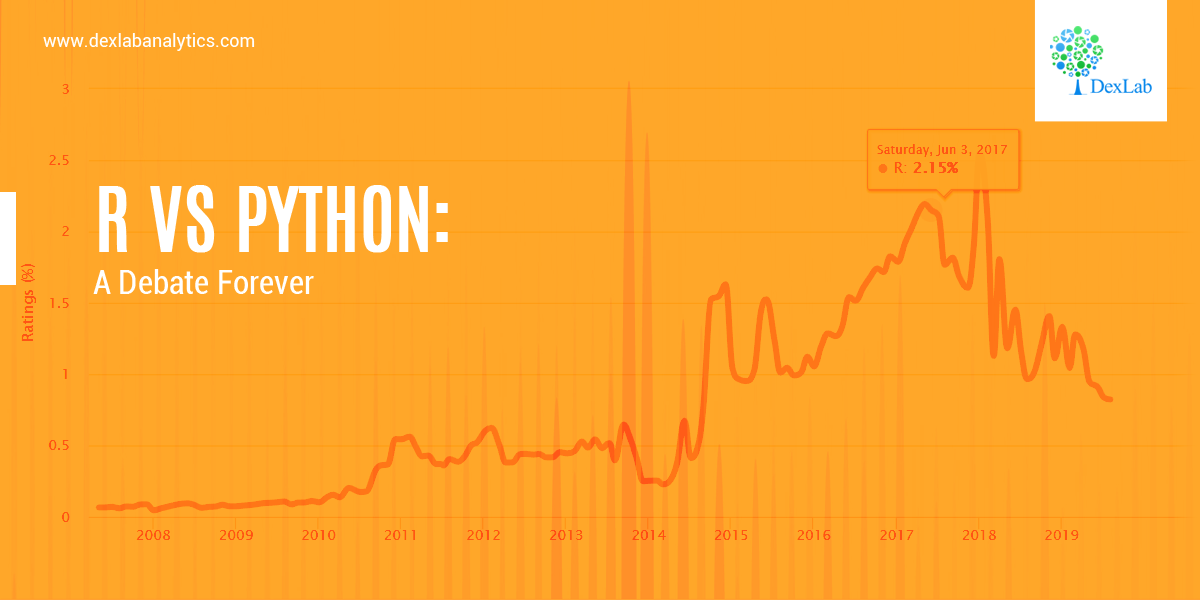
R Vs Python: A Debate Forever
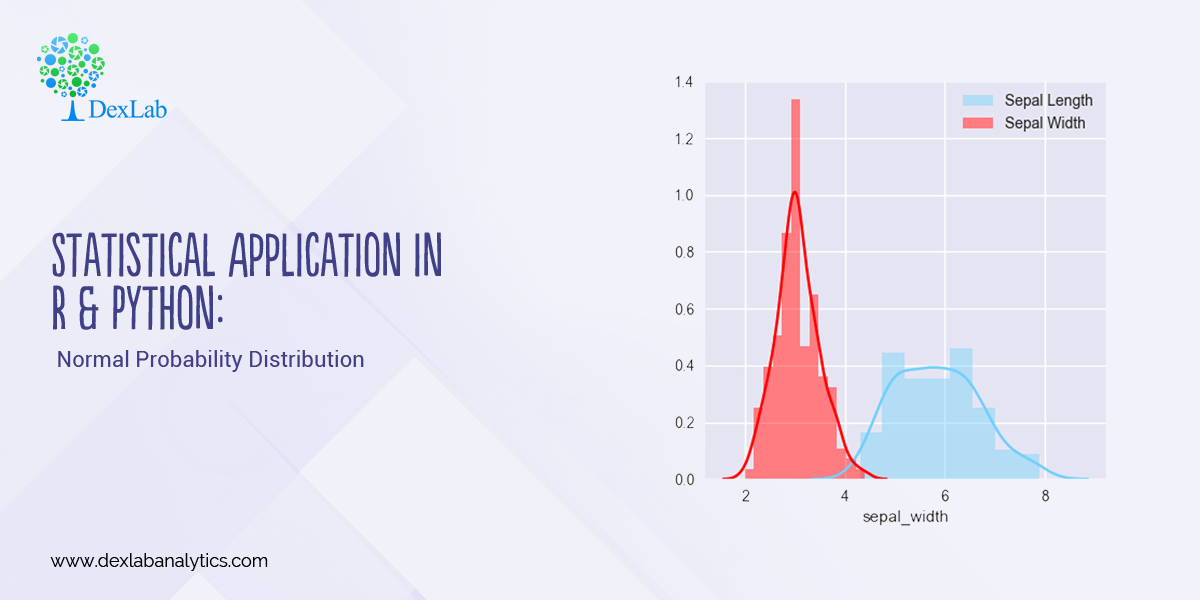
Statistical Application in R & Python: Normal Probability Distribution
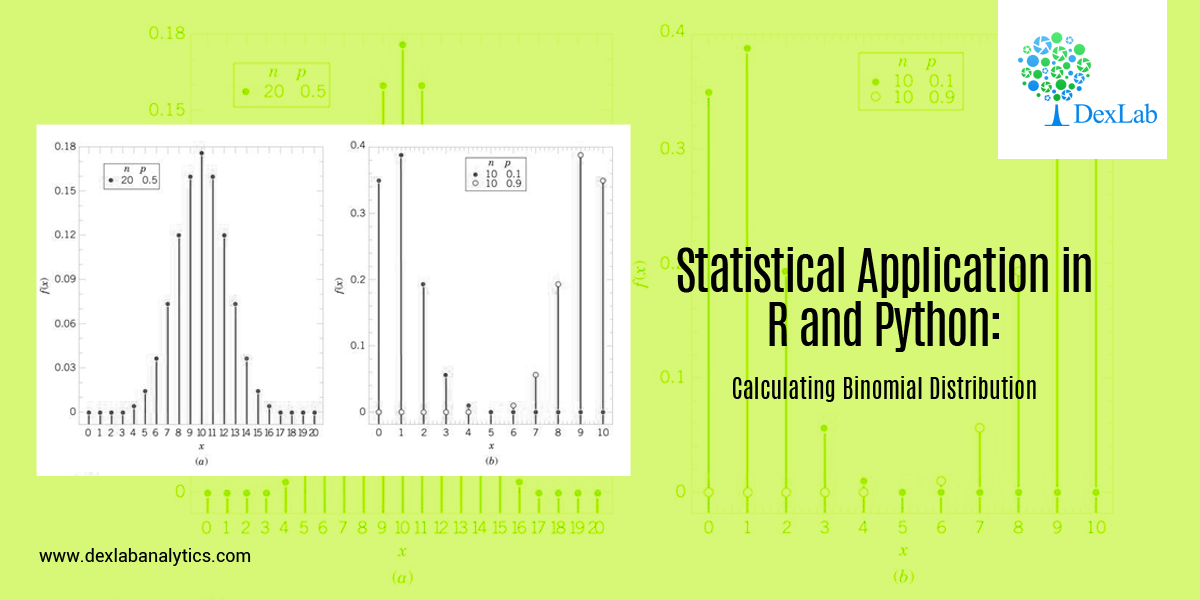
Statistical Application in R and Python: Calculating Binomial Distribution
Bayes’ Theorem: A Brief Explanation
A Beginner’s Guide to Learning Data Science Fundamentals
The Impact of Big Data on the Legal Industry
Big Data Analytics for Event Processing
Transforming Construction Industry With Big Data Analytics
Big Data and Its Influence on Netflix
1
2
3
…
7
Next »
Call us
to know more
Gurgaon
+91 8676079880
Kolkata
+91 9903662244
×