Big data is a very powerful term nowadays. It seems to be a large amount of data. Big data means large amount of structured, unstructured, semi-structured data. We get data continuously from various data sources.

Just have a look on how we get data.
Nowadays we are living in a techno era in which we need to use technology so that’s why we are generating data. If you are doing any type of activity like – driving car, having some shakes in CCD, surfing internet, playing games, emails, social media, electronic media, everything plays a crucial role to develop big data.
Availability of Data in Several Forms:
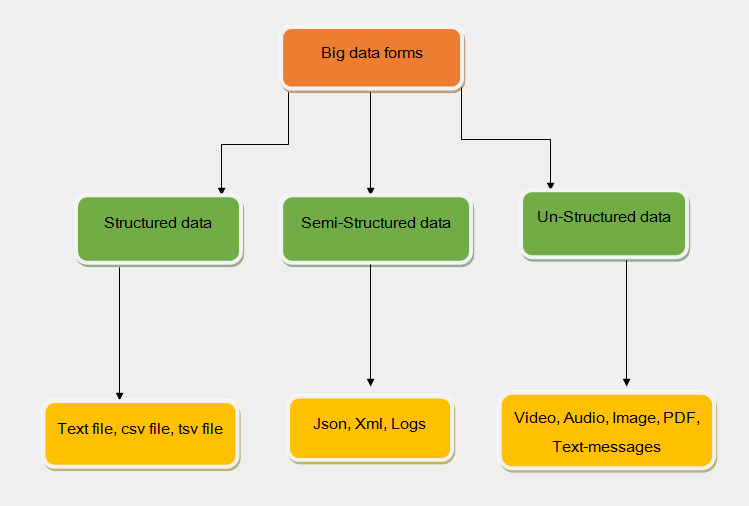
- Structure Data – For developers, structured data is very banal. Structured data is data which we can store in database in table forms like row and columns. Today those data are most processed in the world when we have only 10% of data structured data out of total.
- Semi-structure Data – Semi-structure data doesn’t reside in a relational database and cannot fit easily into relational databases. We get semi-structure data from internet mail accounts, social media, E-commerce. We have only a 5% to 10% data that is in structured way. Semi-structured data is stored in – json, xml, logs.
- Unstructured Data – Unstructured data is not in human readable form, we can’t read unstructured data. We have a number of resources where we are getting unstructured data continuously. As of now, we have 75% unstructured data in the form of videos, audios, text-messages, comments, tag, mails, and images.
Big Data Characteristics:-
- Volume – It is the quantity of generated and stored data or size of data like – Gigabytes, terabytes, petabytes.
- Variety – It is the nature of data or forms of data like – structured, semi-structured data, unstructured data
- Velocity – In this context, we measured speed at which data is processed and generated.

How to Handle Big Data?
Hadoop is developed to provide easily saleability of big data by which we can play with big data in easy manner. Hadoop is the way to handle complex data in the form of logs, json, xml any type of data, Hadoop can manage.
Why Hadoop and Nothing Else?
Hadoop has its own centralized processing system or have good tree structured to handle files. Hadoop helps us to process large volume of data parallel. Hadoop has made complex data easier for us. Hadoop is developed to handle big data.
5 Online Sources to Get Basic Hadoop Introduction – @Dexlabanalytics.
History of Hadoop
Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. In 2003, Google had published whitepaper on Google Distributed File system (GFS), which solved the storage problem of very large files. In 2004, based on GFS architecture, Nutch was implementing open source called the Nutch Distributed Filesystem (NDFS). In 2004, Google published Mapreduce, and in 2005 Nutch developers had started working on Mapreduce in NutchProject. Most of the Algorithms had been ported to run using Mapreduce and NDFS. In February 2006, they moved out of Nutch to form an independent subproject of Lucene called Hadoop. At around the same time, Doug Cutting joined Yahoo!. This was demonstrated in 2008 when Yahoo! announced that its production search index was being generated by a 10,000-core Hadoop cluster.
In January 2008, Hadoop made its own top-level project at Apache. By that time, Hadoop was being used by many other companies like Yahoo, Facebook, and the New York Times.
In April 2008, Hadoop broke a world record to become the fastest system to sort a terabyte of data. Running on a 910-node cluster, Hadoop sorted one terabyte in 209 seconds (just under 3½ minutes), beating the previous year’s winner of 297 seconds.
What to Expect: Top 4 Hadoop Big Data Trends 2017 Reigning the Healthcare Industry – @Dexlabanalytics.
How Hadoop Work?
Hadoop has two main concepts:
- HDFS – Hadoop Distributed File System. Hadoop has its own file system called HDFS. HDFS has its own concepts and own policy to store data or secure data in different manner.
- Map Reduce – Map reduce is a Hadoop processing model or we can say that it’s a programming model of Hadoop to provide data us data accessibility or analytics skills.
Besides all this, there are a wide number of crucial insights and theories based on Hadoop frameworks – to nab them get registered in an excellent Hadoop certification in Pune. DexLab Analytics offer compelling Big Data Hadoop certification in Pune – take a look at!
Interested in a career in Data Analyst?
To learn more about Machine Learning Using Python and Spark – click here.
To learn more about Data Analyst with Advanced excel course – click here.
To learn more about Data Analyst with SAS Course – click here.
To learn more about Data Analyst with R Course – click here.
To learn more about Big Data Course – click here.
Analytics, Basics of Big Data Hadoop, Big Data Analytics, Big data certification, Big data certification pune, Big data courses, big data hadoop, Big Data Hadoop courses, Big Data Hadoop institute in Delhi, Big Data in India, Big Data technologies, Big data training, hadoop training in Pune
Comments are closed here.