
Right data for the right analytics is the crux of the matter. Every data analyst looks for the right data set to bring value to his analytics journey. The best way to understand which data to pick is fact-finding and that is possible through data visualization, basic statistics and other techniques related to statistics and machine learning – and this is exactly where the role of statisticians comes into play. The skill and expertise of statisticians are of higher importance.

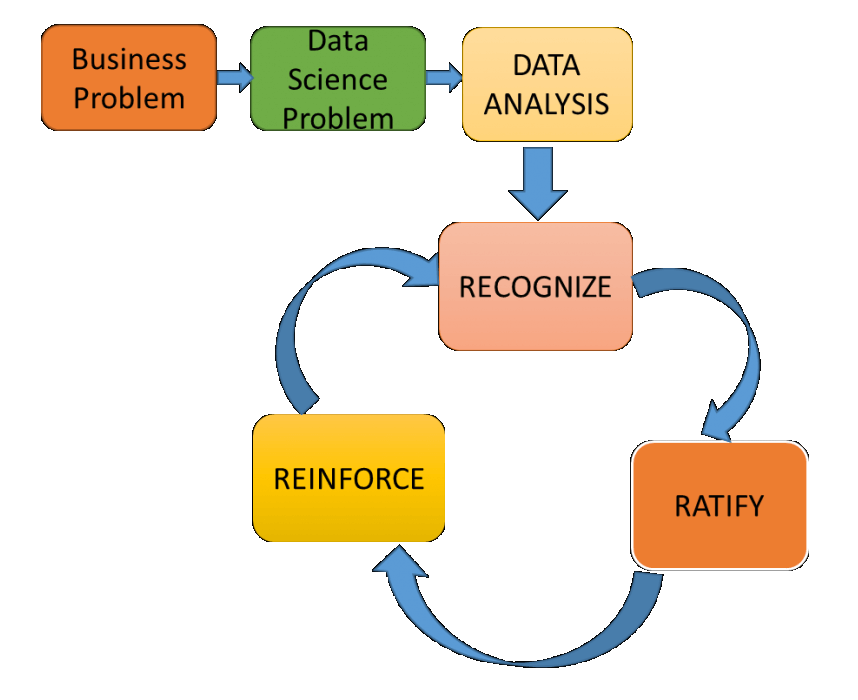
Below, we have mentioned the 3R’s that boosts the performance of statisticians:
Recognize – Data classification is performed using inferential statistics, descriptive and diverse other sampling techniques.
Ratify – It’s very important to approve your thought process and steer clear from acting on assumptions. To be a fine statistician, you should always indulge in consultations with business stakeholders and draw insights from them. Incorrect data decisions take its toll.
Reinforce – Remember, whenever you assess your data, there will be plenty of things to learn; at each level, you might discover a new approach to an existing problem. The key is to reinforce: consider learning something new and reinforcing it back to the data processing lifecycle sometime later. This kind of approach ensures transparency, fluency and builds a sustainable end-result.
Now, we will talk about the best statistical techniques that need to be applied for better data acknowledgment. This is to say the key to becoming a data analyst is through excelling the nuances of statistics and that is only possible when you possess the skills and expertise – and for that, we are here with some quick measures:
Distribution provides a quick classification view of values within a respective data set and helps us determine an outlier.
Central tendency is used to identify the correlation of each observation against a proposed central value. Mean, Median and Mode are top 3 means of finding that central value.
Dispersion is mostly measured through standard deviation because it offers the best scaled-down view of all the deviations, thus highly recommended.
Understanding and evaluating the data spread is the only way to determine the correlation and draw a conclusion out of the data. You would find different aspects to it when distributed into three equal sections, namely Quartile 1, Quartile 2 and Quartile 3, respectively. The difference between Q1 and Q3 is termed as the interquartile range.
While drawing a conclusion, we would like to say the nature of data holds crucial significance. It decides the course of your outcome. That’s why we suggest you gather and play with your data as long as you like for its going to influence the entire process of decision-making.
On that note, we hope the article has helped you understand the thumb-rule of becoming a good statistician and how you can improve your way of data selection. After all, data selection is the first stepping stone behind designing all machine learning models and solutions.
Saying that, if you are interested in learning machine learning course in Gurgaon, please check out DexLab Analytics. It is a premier data analyst training institute in the heart of Delhi offering state-of-the-art courses.
The blog has been sourced from — www.analyticsindiamag.com/are-you-a-better-statistician-than-a-data-analyst
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.
analytics course in delhi, Data analyst certification, Data analyst course, data analyst course in delhi, data analyst institute, Data analyst training institute, data analytics certification courses, Machine Learning Certification, Machine Learning course, Machine Learning course in Gurgaon, Machine Learning course online, Machine Learning Courses, Machine Learning Training
Comments are closed here.