
In the first part of this article, we have seen how to describe and summarize datasets and how to calculate types of measures in descriptive statistics in Python. It’s possible to get descriptive statistics with pure Python code, but that’s rarely necessary.
Python is an advanced programming language extensively used in all of the latest technologies of Data Science, Deep Learning and Machine learning. Furthermore, it is particularly responsible for the growth of the Machine Learning course in India. Moreover, numerous courses like Deep Learning for Computer vision with Python, Text Mining with Python course and Retail Analytics using Python are pacing up with the call of the age. You must also be in line with the cutting-edge technologies by enrolling with the best Python training institute in Delhi now, not to regret it later.
In this part, we will see the Python statistics libraries which are comprehensive, popular, and widely used especially for this purpose. These libraries give users the necessary functionality when crunching data. Below are the major Python libraries that are used for working with data.

NumPy and SciPy – Fundamental Scientific Computing
NumPy stands for Numerical Python. The most powerful feature of NumPy is the n-dimensional array. This library also contains basic linear algebra functions, Fourier transforms, advanced random number capabilities. NumPy is much faster than the native Python code due to the vectorized implementation of its methods and the fact that many of its core routines are written in C (based on the CPython framework).
For example, let’s create a NumPy array and compute basic descriptive statistics like mean, median, standard deviation, quantiles, etc.
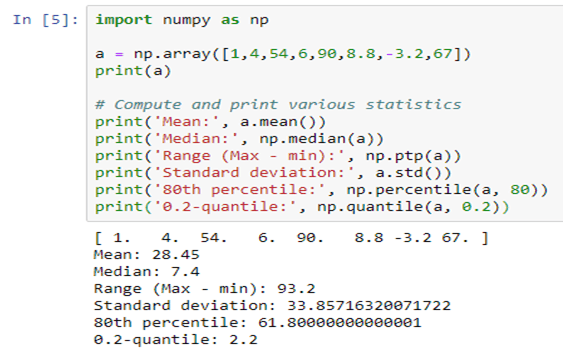
SciPy stands for Scientific Python, which is built on NumPy. NumPy arrays are used as the basic data structure by SciPy.
Scipy is one of the most useful libraries for a variety of high-level science and engineering modules like discrete Fourier transforms, Linear Algebra, Optimization and Sparse matrices. Specifically in statistical modelling, SciPy boasts of a large collection of fast, powerful, and flexible methods and classes. It can run popular statistical tests such as t-test, chi-square, Kolmogorov-Smirnov, Mann-Whitney rank test, Wilcoxon rank-sum, etc. It can also perform correlation computations, such as Pearson’s coefficient, ANOVA, Theil-Sen estimation, etc.
Pandas – Data Manipulation and Analysis
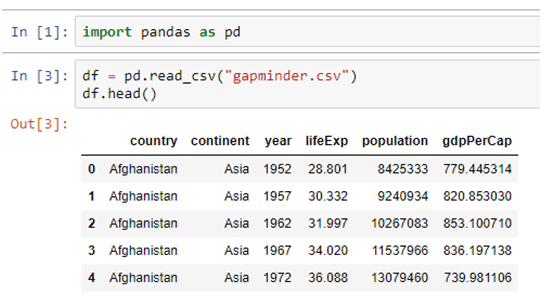
Pandas library is used for structured data operations and manipulations. It is extensively used for data preparation. The DataFrame() function in Pandas takes a list of values and outputs them in a table. Seeing data enumerated in a table gives a visual description of a data set and allows for the formulation of research questions on the data.
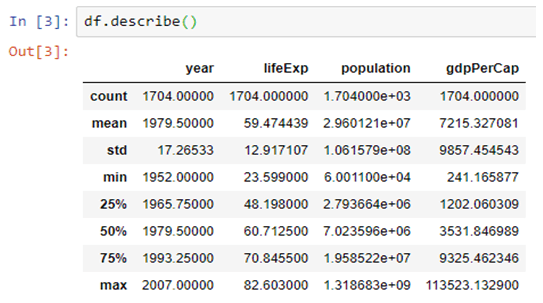
The describe() function outputs various descriptive statistics values, except for the variance. The variance is calculated using the var() function in Pandas.
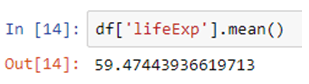
The mean() function, returns the mean of the values for the requested axis.
Matplotlib – Plotting and Visualization
Matplotlib is a Python library for creating 2D plots. It is used for plotting a wide variety of graphs, starting from histograms to line plots to heat plots. One can use Pylab feature in IPython notebook (IPython notebook –pylab = inline) to use these plotting features inline. If the inline option is ignored, then pylab converts IPython environment to an environment, very similar to Matlab.
matplotlib.pylot is a collection of command style functions.
If a single list array is provided to the plot() command, matplotlib assumes it is a sequence of Y values and internally generates the X value for you.
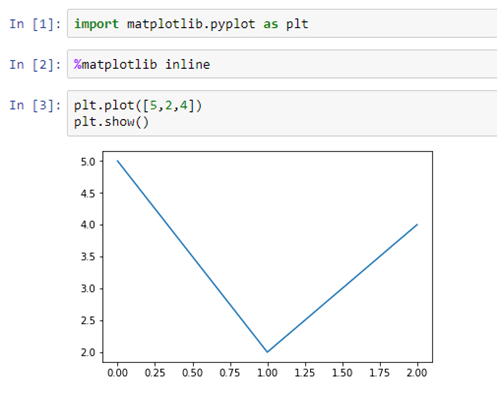
Each function makes some change to a figure, like creating a figure, creating a plotting area in a figure, decorating the plot with labels, etc. Now, let us create a very simple plot for some given data, as shown below:
Scikit-learn – Machine Learning and Data Mining
Scikit-learn built on NumPy, SciPy and matplotlib. Scikit-learn is the most widely used Python library for classical machine learning. But, it is necessary to include it in the discussion of statistical modeling as many classical machine learning (i.e. non-deep learning) algorithms can be classified as statistical learning techniques. This library contains a lot of efficient tools for machine learning and statistical modeling including classification, regression, clustering and dimensional reduction.
Conclusion
In this article, we covered a set of Python open-source libraries that form the foundation of statistical modelling, analysis, and visualization. On the data side, these libraries work seamlessly with the other data analytics and data engineering platforms, such as Pandas and Spark (through PySpark). For advanced machine learning tasks (e.g. deep learning), NumPy knowledge is directly transferable and applicable in popular packages such as TensorFlow and PyTorch. On the visual side, libraries like Matplotlib, integrate nicely with advanced dashboarding libraries like Bokeh and Plotly.
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.
deep learning certification, deep learning course, Deep Learning Training, Deep Learning Training Courses, Deep learning Training Institutes, Machine Learning, Machine Learning Certification, Machine Learning course, Machine Learning course in Gurgaon, Machine Learning Courses, Machine Learning Training, Machine Learning Using Python, Python certification, python certification course, Python courses, python data science course, Software tools : SAS, R, Python etc
Comments are closed here.